
梳理 Nansen、Dune 等市场上主流的面向个人用户的数据分析平台。
原文标题:《IOSG Weekly Brief |链上数据分析平台现状与展望 #132》
撰文:Yang,IOSG Ventures
「数」中自有黄金屋,链上数据潜藏着无尽的 Alpha。当我们跟随 smart money 闻风而动,当我们夜以继日地在 NFT Paradise 中寻找 trending NFT,当我们查询 StepN 每日新鞋铸造数据时,你是否好奇这些数据如何而来?面对众多链上数据分析平台和纷繁复杂的功能,你是否还在寻找最适合自己的那个平台?
背景介绍
随着链上生态的日益蓬勃,如 DeFi 交易、借贷,NFT 的铸造、交易等,用户的行为被直接透明地记录在链上。这些链上行为的数据对应着链上价值的流动,对这些数据的分析和根据分析而得出的洞察和见解变得极为有价值。链上数据分析平台,如 Nansen,Token Terminal,Dune Analytics,Footprint Analytics,flipsidecrypto, glassnode,Skew 等顺应这些日益增长的需求,面向个人和机构用户推出了侧重点略有不同的产品。
本文先将简述链上数据分析平台背后的数据架构,意在告诉读者那些链上数据分析结果从何而来,如何而来。随后我们从数据丰富度 (覆盖区块链数量)、数据粒度、数据延迟、平台易用性和查询自由度等维度为读者梳理市场上主流的面向个人用户的数据分析平台。最后分享我们对 Web3 未来链上数据索引、查询和分析的一点畅想。
链上数据分析平台数据架构介绍
虽然区块链记录着所有原始的交易数据,链上数据本身都是公开透明的,但当我们提出:过去 24 小时 Uniswap 的交易量是多少?当前百分之多少的 BAYC 持有者也同时持有至少一个 Moonbirds?...... 等等问题时,链上原始数据并不能给我们答案,我们需要通过索引 (indexing),处理 (processing),存储 (storage) 等等一系列数据摄取 (ingestion) 的处理过程,再根据所提问题来聚合运算对应的数据,才能得到问题的答案。直接查询区块链来求得问题答案是非常耗时耗力的,为了让链上数据能够被快速检索,当前主流的链上数据分析平台会将索引得到的原始链上数据,经过一系列处理后,存入由平台负责更新和管理的数据仓库 (data warehouse) 中。当用户在 Nansen 追踪 smart money 的交易动态,或在 Dune Analytics 上查看可视化分析时,用户对所谓「链上数据」的查询,实际上是在查询由项目方中心化控制的数据库而非区块链本身。
链上数据分析平台的数据仓库架构大致如下:
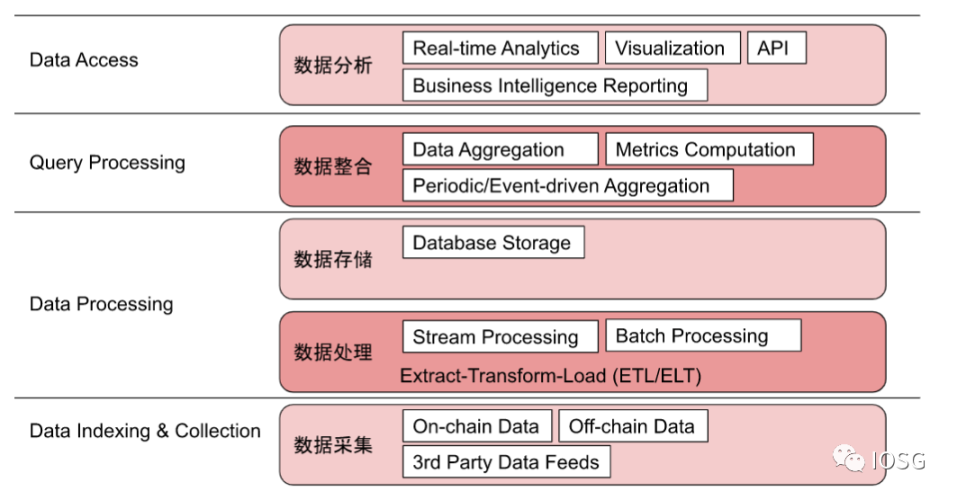
数据采集层:平台从区块链节点获取原始链上数据,部分平台会接受第三方提供的数据源,还有的平台 (如 Footprint Analytics) 支持用户上传链下数据来辅助最终的数据分析。
数据处理层:各平台将原始数据以流式处理或批次处理的方式进行数据抽取、转换和加载。流式处理中,实时原始数据被源源不断地输入并被持续处理,通常意味着数据延迟低,分析结果时效性更高;而批次处理虽然数据延迟会稍高,分析结果时效性稍低,但更适用于大容量的数据处理。
数据存储层:经过处理后的数据会根据平台方预先定义的格式存储进数据集的各数据表中以待后续使用。
数据整合层:存储的数据会被聚合运算。计算可以是根据预先设定好的指标来进行的 (metrics computation),也可以阶段性的 (periodic) 或是根据设定好的条件被触发的 (event-driven aggregation) 等。
数据分析层:运算完成的结果被实时地报告、输出。对于个人用户而言,我们主要在数据分析层与链上数据分析平台进行交互,比如 Nansen 提供的 Business Intelligence 报告界面,Dune Analytics 和 Footprint Analytics 上众多的的可视化图表,以及部分平台提供的 API 接口等。
各平台采取了不同的方案来建设和维护自己的数据仓库。比如 Nansen 借助第三方 Google Cloud Platform 完成数据仓库的建设和维护。
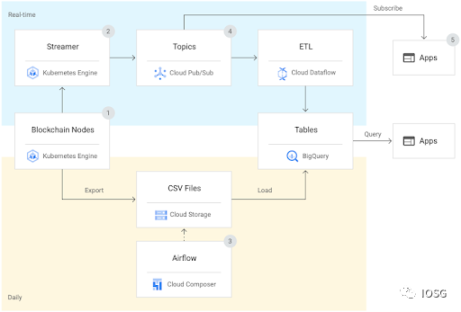
图片来源:Google Cloud Nansen Case Study,https://cloud.google.com/customers/nansen
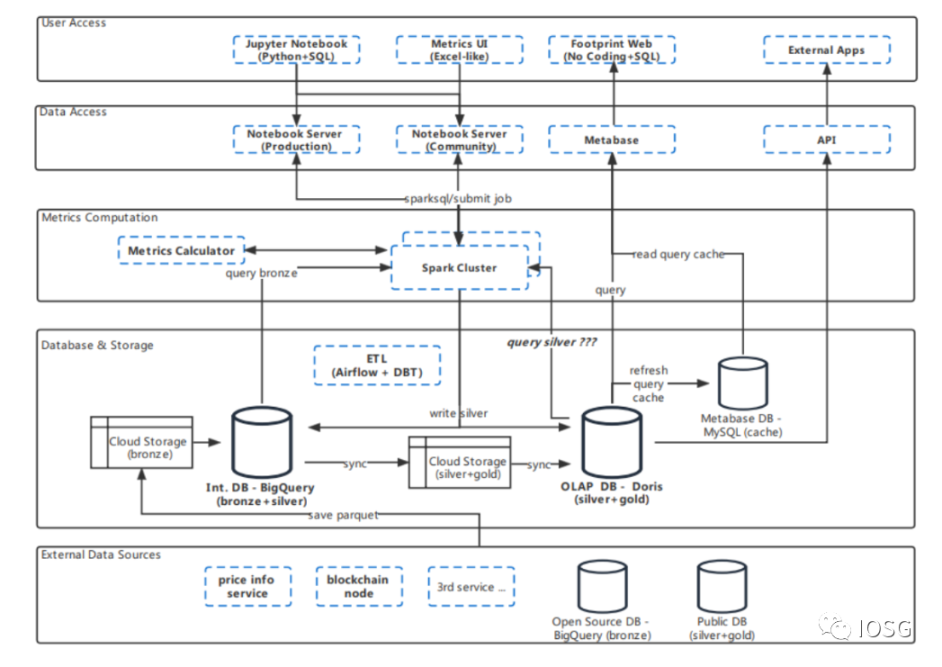
而 Dune Analytics,Footprint Analytics,Token Terminal 等平台则独立建设和维护自己的数据仓库。以 Footprint Analytics 为例,其数据仓库架构如下图所示。
主流链上数据分析平台比较
本节以内容视角和用户视角,从数据丰富度 (覆盖区块链数量)、数据粒度、数据延迟、平台易用性和查询自由度等维度来对比几家主流的链上数据分析平台,包括 Nansen,Token Terminal,Dune Analytics,Footprint Analytics。
部分平台给用户提供标准化的信息报告界面,比如 Nansen,Token Terminal 等。
Nansen
Nansen 应该是大家最为熟悉的链上数据分析平台之一。相较于其他平台,其最为出色的功能是钱包标记 (wallet profiler/wallet labeling)。借助钱包标记并结合其他链上数据为用户提炼出极具价值的信息,比如 Smart Money,帮助用户追踪巨鲸、重度 DeFi 玩家的实时动向。其他热门产品包括 Hot Contract, 发现新兴热门的 DeFi 和 NFT 合约;NFT Paradise,一览实时 NFT 铸造数据等等。
- 【覆盖区块链】Nansen 现在支持 Ethereum, Arbitrum, Avalanche, BSC, Celo, Fantom, Optimism, Polygon, Ronin, Terra, Solana 共计 11 条区块链的链上数据分析
- 【数据粒度】Nansen 普通版仅为用户提供精选数据(curated data)
- 【数据延迟】流式处理和批次处理。部分数据分析已实现近乎实时的报告
- 【平台易用性】零门槛
- 【查询自由度】Nansen 普通版仅提供标准信息模板界面。针对机构客户对自定义链上数据查询和分析的需求,Nansen 借助 Google Cloud Platform 的 Blockchain Datasets 发布了 Nansen Institutions 产品,让专业 / 机构用户能够编写满足定制需求的 SQL Queries。
值得一提的是,Nansen 在 Nansen Research 频道中发布了不少链上分析报告。研究报告会对重点事件进行抽丝剥茧般的链上追踪和分析,读者不妨偶尔阅读这些报告 (如 Nansen 针对上月 stETH 脱锚事件发布的报告),对学习链上分析的方法大有裨益。
Token Terminal
Token Terminal 以提供准确的协议收入 (protocol revenue) 而著名。基于协议收入,Token Terminal 计算了各协议的市销率(P/S),市盈率(P/E)等数据。这些数据在一定程度上为各协议提供了估值基准。
- 【覆盖区块链】Token Terminal 追踪了超过 130 个协议的数据
- 【数据粒度】Token Terminal 仅为用户提供精选数据(curated data)
- 【数据延迟】批次处理。据 IOSG 团队近期与 Token Terminal 的沟通,目前 Token Terminal 平台上的数据大约有两天时间的延迟
- 【平台易用性】零门槛
- 【查询自由度】仅提供标准信息界面
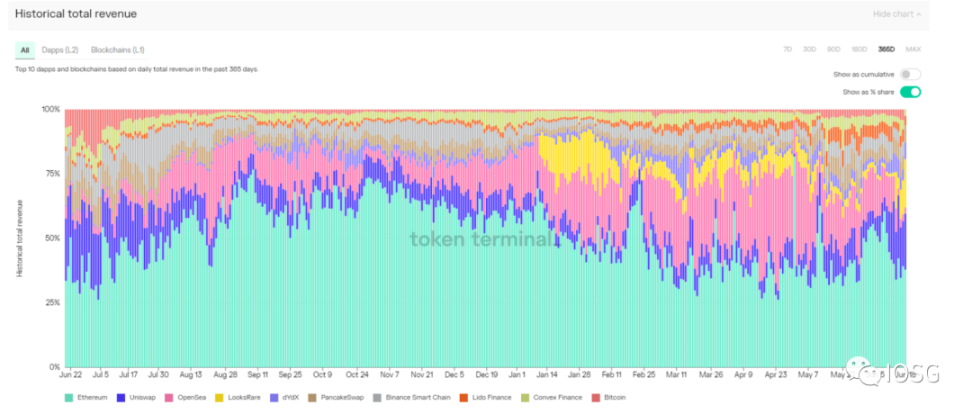
Token Terminal 协议收入数据图例:过去 365 天收入前十的区块链和协议的收入占比
另外一些主流链上数据分析平台则向用户开放数据表,用户可自由编写代码进行查询,在查询内容上给予用户一定的自由度,如 Dune Analytics 和 Footprint Analytics。
Dune Analytics
Dune Analytics 是最早开放用户自主查询的链上数据分析平台,拥有最大的分析师团体和用户社区。Dune Analytics 提供了高度颗粒化的原始链上数据,分析师可以自由地利用这些数据写出自定义的查询。Dune Analytics 也对项目方团队开放 Abstraction,项目方可以根据自己协议的数据内容创造更适合的数据表供分析师使用。但自主查询具备一定的门槛,分析师需具备 PostgreSQL 的编写能力才能创造满足自己需求的数据查询。而且查询延迟与分析师 SQL 编写水平和对 Dune Analytics 提供的数据表熟悉程度高度相关。
- 【覆盖区块链】Dune Analytics 提供了 Ethereum, BSC, Optimism, Polygon, Gnosis Chain, Solana 共计 6 条区块链的链上数据
- 【数据粒度】极细
- 【数据延迟】流式处理。数据延迟大约五分钟
- 【平台易用性】Dune Analytics 对分析师提出了一定的 SQL coding 要求
- 【查询自由度】高
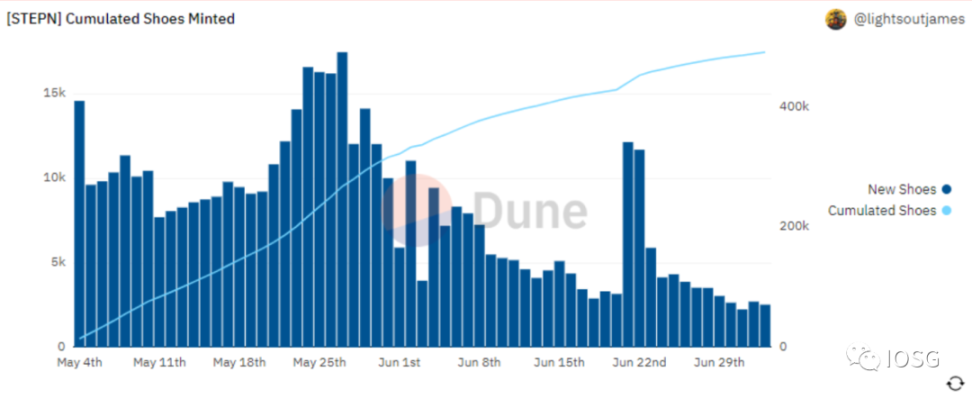
有了高度颗粒化的原始数据,分析师便可以在 Dune Analytics 自由创建链上分析,如每日 StepN 新鞋铸造及历史积累数据 。
Dune Analytics 于 2022 年 5 月 30 日发布了 Dune Engine v2。Dune Engine v2 在将 Dune Analytics 的数据架构进行大改来为用户提供更快查询响应和更好查询表现的同时,也将对用户体验的影响降至最低。
Footprint Analytics
相较于 Nansen 低使用门槛但仅提供标准化信息界面,Dune Analytics 提供了自由查询但又要求分析师具备编写 PostgreSQL 语言的能力,Footprint Analytics 为用户提供了两全其美的解决方案,在给予极大的查询自由度的同时降低了使用门槛。它是如何做到的?
「链上数据错综复杂,分析师可能需要写成百上千行代码才得以完成一个指标的计算。为了解决分析门槛高的问题,Footprint 清理和集成链上数据,给数据赋予了业务意义,使得用户无需 SQL 查询和编码也可以分析区块链数据。任何人都可以通过丰富的图表界面在几分钟内构建自己的自定义图表,解密链上数据,发现项目背后的价值趋势。」
Footprint Analytics 不仅提供原始区块链数据,更将链上数据进行分级。最原始的链上数据为铜级别 (Bronze data),经过筛选、清洗和增强的数据为银级别 (Silver data),进一步整理出具备业务意义的数据为金级别 (Gold data)。
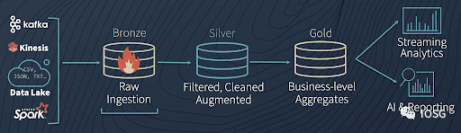
已经整理完成的具有商业逻辑和业务意义的金银级别数据可以直接用于分析。借助金银级别数据,Footprint Analytics 为用户提供了通过简单地拖拽数据表就能自主查询链上数据的服务。不管读者你是否会写类 SQL 语言代码,你都可以快速创建满足自己定制化需求的数据分析信息界面,并将所需信息通过直观且可互动的图表可视化。
- 【覆盖区块链】Footprint Analytics 目前提供了 Ethereum,Arbitrum,Avalanche,Boba,BSC,Celo,Fantom,Harmony,IOTEX,Moonbeam,Moonriver,Polygon,Thundercore,Solana 等共计 17 条区块链的链上数据
- 【数据粒度】Footprint Analytics 既为用户提供粒度极细的原始数据,也为用户提供精选数据(curated data)
- 【数据延迟】目前 Footprint Analytics 对采集到的原始数据进行每日一次的批次处理,数据延迟为一天
- 【平台易用性】在 Footprint Analytics 平台,用户无需 SQL 查询和编码也可自由分析链上数据。对于具备 SQL 代码能力的分析师,Footprint 也提供原始数据供分析师发挥。
- 【查询自由度】高
读者不妨现在就前往 Footprint Analytics,几分钟即可上手制作一个自己的链上分析界面
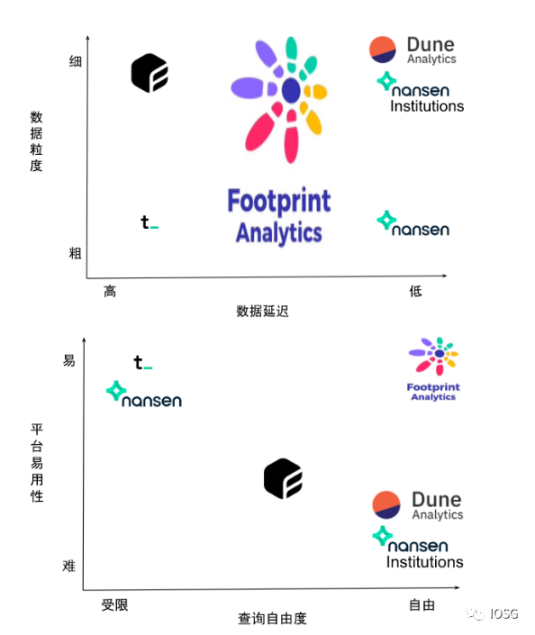
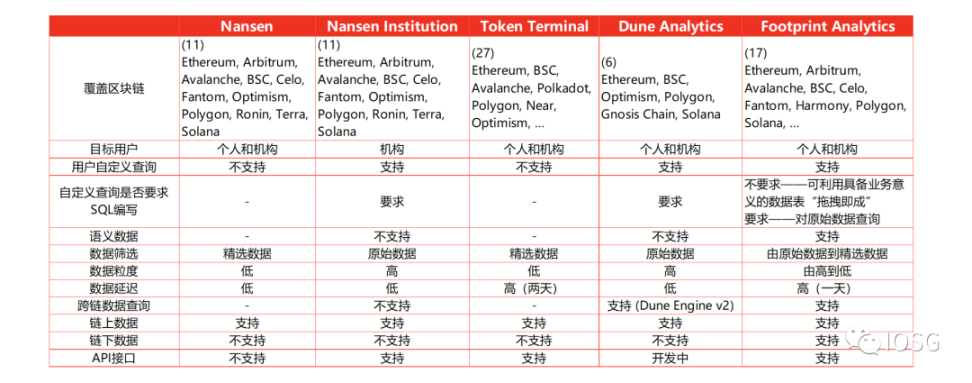
图片来源:IOSG
一点畅想 —— 去中心化链上数据分析
链上数据分析如此重要,当今用户却只能依赖 Nansen,Dune Analytics 等中心化管理的「链上数据」分析平台来辅助投资决策。在这些平台上,用户无法验证所用数据是否未经篡改,不得不信任平台所提供的数据集是确凿真实的。「Don’t Trust. Verify.」在链上数据分析这里成了一句空话。
Web3 浪潮滚滚而来,链上生态越发丰富,未来的智能合约和去中心化应用可能不仅仅需要原始链上数据和预言机所提供的数据作为输入信息,还可能需要输入基于链上原始数据计算得出的分析结果,那时候我们还能信任和使用这些中心化链上数据分析平台作这类用途吗?答案恐怕是否定的。
IOSG 团队近期看到已有项目团队在实现去中心化链上数据查询和分析的道路上迈出了第一步。由于篇幅受限,且听下回分解 —— 通向去中心化链上数据分析之路。
https://www.nansen.ai/post/nansen-and-google-cloud-empower-web3-investors-with-high-quality-real-time-market-intelligence
https://cloud.google.com/customers/nansen
https://www.nansen.ai/research/on-chain-forensics-demystifying-steth-depeg
https://docs.dune.com/data-tables/data-tables
https://docs.dune.com/dune-engine-v2-beta/query-engine
https://www.footprint.network/@Footprint/Footprint-Datasets-Data-Dictionary
https://www.youtube.com/watch?v=Pp9_wgYZB3I
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。

































